How to Design a Multi-Source Snowflake Data Platform Without Creating Chaos
Dara Bindara

1. Executive Summary
Organizations often integrate multiple data sources—including APIs, SaaS tools, and databases—into Snowflake without a clear architecture. This lack of structure inevitably results in duplicate pipelines, inconsistent schemas, broken downstream analytics, and high operational overhead.
A well-designed multi-source Snowflake platform requires:
- Standardized ingestion patterns (batch, CDC, and streaming)
- Unified data modeling strategy
- Strong governance and ownership
- Orchestration and failure handling
- Incremental and idempotent pipelines
Recommended Approach / Pattern
Design a centralized but modular data platform characterized by a standard ingestion framework, a layered architecture (Bronze/Silver/Gold), and source-specific isolation coupled with shared transformation standards.
Where It Fits (Best Use Cases)
- Organizations integrating 5+ data sources (CRM, Finance, HR, Product, etc.)
- Enterprises building a centralized data warehouse
- Teams implementing analytics, reporting, or ML on unified data
- Platforms requiring incremental ingestion and near real-time updates
Key Outcomes
Implementing this framework leads to consistent and reliable datasets, reduced pipeline duplication, easier onboarding of new data sources, and a scalable architecture for analytics and AI.
2. Background
Modern enterprises rely on a diverse stack of systems such as Salesforce (CRM), Sage Intacct (Finance), and ADP (HR). Most teams integrate these systems independently, which leads to conflicting business logic and the absence of a single source of truth.
Snowflake provides the centralized storage required for these operations, but without proper design, it risks becoming a data dumping ground rather than a high-performance platform.
3. Problem
Integrating multiple sources without a structured approach causes significant technical debt.
3.1 Symptoms
- Symptom 1 — Duplicate Pipelines: The same data is ingested multiple times using different logic.
- Symptom 2 — Schema Chaos: Inconsistent naming conventions and structures across various sources.
- Symptom 3 — No Ownership: Lack of clear data owners leading to a total lack of accountability.
- Symptom 4 — Broken Pipelines: Failures aren't handled gracefully, resulting in silent data corruption.
- Symptom 5 — No Incremental Strategy: Relying on full reloads instead of incremental processing, driving up cost and latency.
- Symptom 6 — Weak Orchestration: Missing dependency management and retry logic.
3.2 Impact
These symptoms result in conflicting metrics across teams, high maintenance effort, data trust issues, and an inability to scale the platform effectively as the business grows.
4. Requirements & Assumptions
4.1 Data & SLA
- Support for multiple heterogeneous sources.
- Mandatory incremental data ingestion.
- Daily to near real-time updates with support for late-arriving data.
4.2 Security & Access Control
- RBAC with the principle of least privilege.
- Source-level data isolation and PII masking/classification.
- Comprehensive audit logging.
4.3 Tooling & Constraints
- Core Platform: Snowflake
- Staging: AWS S3
- Orchestration: Airflow or AWS Step Functions
Constraints: Must handle schema evolution across sources, API rate limits, and inherent data inconsistencies across source systems.
5. Recommended Architecture
5.1 High-Level Flow
To scale across multiple sources, the architecture must transition from isolated silos to a structured pipeline:
- Extraction: Pull data from diverse sources (APIs, DBs, SaaS).
- Landing: Store raw data in an S3 landing zone for durability.
- Bronze Layer: Load into Snowflake as-is for traceability.
- Silver Layer: Standardize and clean data into unified schemas.
- Gold Layer: Transform into business-ready dimensions and facts.
- Serving: Deliver data for analytics, dashboards, and ML models.
5.2 Architecture Diagram
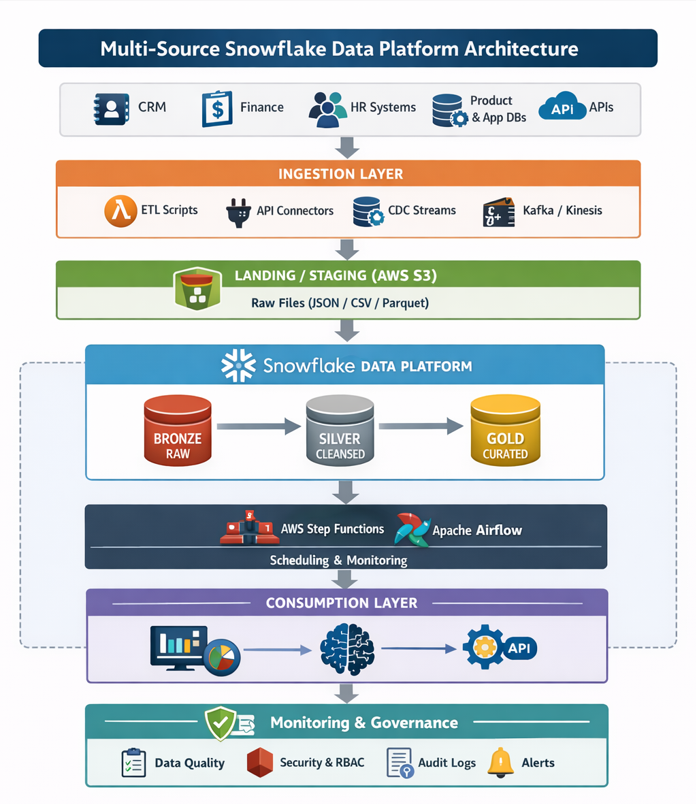
5.3 Options
Option A — Ad-hoc Source Integration
- Advantages: Faster initial setup for 1–2 sources; minimal upfront effort; useful for quick POCs.
- Disadvantages: No standardization leads to inconsistent schemas; high logic duplication; difficult to onboard new sources; high long-term maintenance costs.
Option B — Standardized Multi-Source Platform (Recommended)
- Advantages: Reusable framework; consistent transformation standards; easier onboarding; strong governance and observability.
- Selection Guide: Organizations planning enterprise AI or large-scale analytics initiatives should adopt this "AI-ready" approach.
6. Implementation
6.1 Setup
Successful implementation requires a clean split between compute and storage resources.
- Snowflake: Databases/schemas, dedicated warehouses for ingestion vs. transformation, and RBAC.
- Infrastructure: S3 for raw storage, an orchestrator (Airflow/Step Functions), and a metadata tracking system.
6.2 Core Build Steps
Step 1 — Standardized Ingestion Framework
Build reusable connectors and implement incremental extraction based on offsets or timestamps. Ensure loads are idempotent to prevent duplicate records during retries.
Step 2 — Raw Data Isolation (Bronze Layer)
Store source-wise raw data as immutable records. Use append-only strategies to maintain a perfect audit trail of what was received from the source.
Step 3 — Data Standardization (Silver Layer)
Normalize schemas and naming conventions across disparate sources (e.g., standardizing created_at vs. entry_date). Apply schema evolution handling to prevent source changes from breaking downstream models.
Step 4 — Business Transformation (Gold Layer)
Create unified business models. This is where you define shared KPIs like "Monthly Recurring Revenue" or "Active Users" to ensure every department sees the same numbers.
Step 5 — Orchestration & Incremental Processing
Manage dependencies between layers. Use watermark tracking to process only new or changed data, avoiding expensive full reloads while ensuring no data gaps exist.
6.3 Configuration Defaults
- Auto-suspend warehouses: Set to immediate to minimize idle credit consumption.
- Resource monitors: Set hard limits to prevent cost overruns.
- Logging: Maintain audit tables for every pipeline run (start time, end time, rows processed).
7. Validation & Testing
Validation is the cornerstone of a reliable multi-source platform. Without automated checks, cross-source inconsistencies can go unnoticed until they break downstream analytics.
7.1 Data Validation
Standard validation checks should be integrated into every pipeline run:
- Row Count Checks: Verifying that the number of records moved between layers (Bronze to Silver to Gold) is consistent.
- Duplicate Detection: Ensuring primary keys remain unique after multiple source merges.
- Freshness Validation: Confirming that the data is up-to-date and within the expected SLA window.
7.2 Reconciliation
Periodic reconciliation ensures that curated datasets remain in sync with the source systems over time. Key activities include:
- Source vs. target record comparisons.
- Feature dataset completeness checks for ML readiness.
- Validation of incremental ingestion to ensure no "data gaps" occurred during offset shifts.
8. Security & Access
Security practices for a multi-source environment focus on isolation and the principle of least privilege:
- Snowflake RBAC policies: Defining clear roles for Data Engineers (write access) and Data Scientists (read-only access to Gold).
- Role Separation: Ensuring that accidental changes in one source don't impact others.
- Secure Credential Management: Leveraging AWS Secrets Manager for all API and DB connectors.
- Audit Logging: Continuous monitoring through Snowflake query history to track data lineage and access.
9. Performance & Cost
9.1 Performance Considerations
Optimizing for performance involves more than just warehouse size; it requires smart data organization:
- Dedicated ML Warehouses: Separating heavy transformation or training workloads from standard BI reporting warehouses.
- Query Optimization: Focusing on feature generation efficiency to reduce latency.
- Partitioning: Structuring large datasets to take advantage of Snowflake’s micro-partitioning.
9.2 Cost Drivers
- Compute: Virtual warehouse usage for ingestion and complex transformations.
- AI/ML Workloads: High-intensity training pipelines and LLM inference operations.
- Storage: Long-term retention of raw and curated datasets.
9.3 Cost Controls
To keep costs predictable, implement Warehouse Auto-suspend (set to immediate for ingestion), Resource Monitors with hard credit caps, and optimized storage strategies like clustering only critical tables.
10. Operations & Monitoring
10.1 What to Monitor
- Pipeline success/failure rates.
- Data freshness and ingestion latency.
- Data quality scores.
- Real-time compute credit usage.
10.2 Alerting
Automated alerts should trigger via Slack or Email for pipeline failures, significant data delays, or validation anomalies.
10.3 Runbook (Top Issues)
| Issue | Resolution |
|---|---|
| Missing data from source | Check ingestion logs + API limits |
| Duplicate records | Validate deduplication logic in Silver layer |
| Cost spike | Review warehouse usage and query profile |
11. Common Pitfalls
- Building source-specific pipelines without a standardized framework.
- Ignoring incremental loading in favor of easier (but expensive) full reloads.
- Failing to implement a centralized orchestration layer.
- Mixing raw and transformed data in the same schema, leading to a "data swamp."
12. Variations / Use Cases
The beauty of a standardized multi-source architecture is its versatility. Once the framework is in place, it can power a variety of business-critical initiatives:
- Variation 1 — Customer 360 Platform: Unify fragmented customer data from CRM (Salesforce), product usage, and support tickets (Zendesk) to create a single, consistent customer view for personalized marketing and success tracking.
- Variation 2 — Financial Reporting Consolidation: Combine data from multiple global finance systems to produce standardized, accurate financial reports, ensuring "one version of the truth" for CFOs and stakeholders.
- Variation 3 — HR + Payroll Analytics: Integrate HR management and payroll data to analyze workforce trends, compensation equity, and employee attrition patterns.
- Variation 4 — Product Usage Analytics: Merge application event data with user metadata to track behavior, engagement, and feature adoption rates at scale.
13. Appendix
Technologies Used
The following stack is recommended for building a production-grade, multi-source Snowflake platform:
- Snowflake: Central data warehouse and transformation engine.
- AWS S3: Durable landing zone for raw source data.
- Python & SQL: Primary languages for extraction logic and transformations.
- Orchestration Tools: Managing complex dependencies (e.g., Airflow, AWS Step Functions).
Conclusion
Building a Snowflake platform that handles multiple sources is not just about moving data; it’s about creating a governed, scalable environment that the business can trust. By moving away from ad-hoc, source-specific pipelines and adopting a standardized, layered architecture, organizations can reduce overhead, ensure metric consistency, and lay the perfect foundation for advanced analytics and AI.

Dara Bindara
Associate Data Engineer
Boolean Data Systems

Dara Bindara is a Associate Data Engineer specializing in building and optimizing cloud-based data pipelines. Experienced in Python, SQL, PySpark, Snowflake Cortex, and AI/ML workflows, with a focus on ETL automation, large-scale data transformation, and scalable data warehousing.
About Boolean Data
Systems
Boolean Data Systems is a Snowflake Premier Partner that implements solutions on cloud platforms. We help enterprises make better business decisions with data and solve real-world business analytics and data challenges.
Services and
Offerings
Follow us on
Solutions &
Accelerators
Global
Head Quarters
USA - Atlanta
3970 Old Milton Parkway,
Suite #200, Alpharetta, GA 30005
Ph. : 770-410-7770
Fax : 855-414-2865