Batch, CDC, or Streaming: Selecting the Optimal Data Ingestion Strategy for Snowflake
Jagadishwar Pannala

1. Executive Summary
Modern data platforms must select between batch, CDC, and streaming ingestion patterns to meet varying workload requirements. Choosing the wrong approach can lead to increased costs, latency, and operational complexity.
A context-driven strategy that aligns ingestion patterns with data volume, latency requirements, and system constraints is essential. This ensures scalable, efficient, and maintainable Snowflake architectures.
This approach is best suited for enterprises managing hybrid workloads, including reporting, transactional systems, and real-time analytics. It enables flexibility while maintaining architectural consistency.
Key outcomes include improved data reliability, optimized compute utilization, reduced latency, and stronger governance. It also ensures alignment between technical design and business expectations.
Readers will gain a structured framework to evaluate ingestion patterns and implement a hybrid architecture in Snowflake. This includes decision criteria, implementation guidance, and operational best practices.
2. Background
Modern enterprises rely on Snowflake as a centralized data platform for analytics, reporting, and advanced data applications. Data is ingested from diverse sources such as transactional databases, SaaS platforms, APIs, and event streams, each requiring different ingestion approaches.
Batch, CDC, and streaming ingestion patterns are widely adopted, but selecting the appropriate one for each workload remains a challenge. Without a standardized framework, organizations often over-engineer real-time pipelines or rely on batch processes that fail to meet business SLAs.
3. Problem
3.1 Symptoms
- Delayed data availability: Infrequent batch pipelines result in stale data, limiting the ability to generate timely insights and impacting business responsiveness.
- Unnecessary infrastructure costs: Streaming pipelines are often implemented without clear real-time requirements, increasing compute and operational overhead.
- Data inconsistencies across systems: Incomplete CDC implementations fail to capture updates and deletes accurately, leading to mismatched datasets.
- Operational complexity and maintenance overhead: Multiple ingestion patterns without standardization create challenges in monitoring, troubleshooting, and scaling pipelines.
3.2 Impact
An ineffective ingestion strategy affects data freshness, cost efficiency, and scalability. Over time, this results in reduced trust in data, delayed decision-making, and increased engineering effort to maintain complex pipelines.
4. Requirements & Assumptions
4.1 Data & SLA
- Data volume considerations: Systems typically process millions to billions of records per month, requiring ingestion pipelines that can scale efficiently with growing data volumes.
- Freshness and latency requirements: Data freshness expectations range from batch processing (hours/days) to near real-time ingestion (seconds), depending on business use cases.
- Environment setup: Standard environments include Development, UAT, and Production, ensuring proper testing, validation, and controlled deployment.
4.2 Security & Compliance
- Data sensitivity and regulatory requirements: Ingestion pipelines often handle sensitive data such as PII, requiring compliance with governance and regulatory standards.
- Access control model: Role-Based Access Control (RBAC) with secure service accounts ensures controlled access and auditability across environments.
4.3 Tooling & Constraints
- Ingestion and orchestration tools: Common tools include Snowflake Streams & Tasks, Airflow, dbt, and third-party ingestion platforms for pipeline orchestration and transformation.
- System constraints and limitations: Constraints such as API rate limits, schema evolution, network latency, and data ordering must be considered when designing ingestion pipelines.
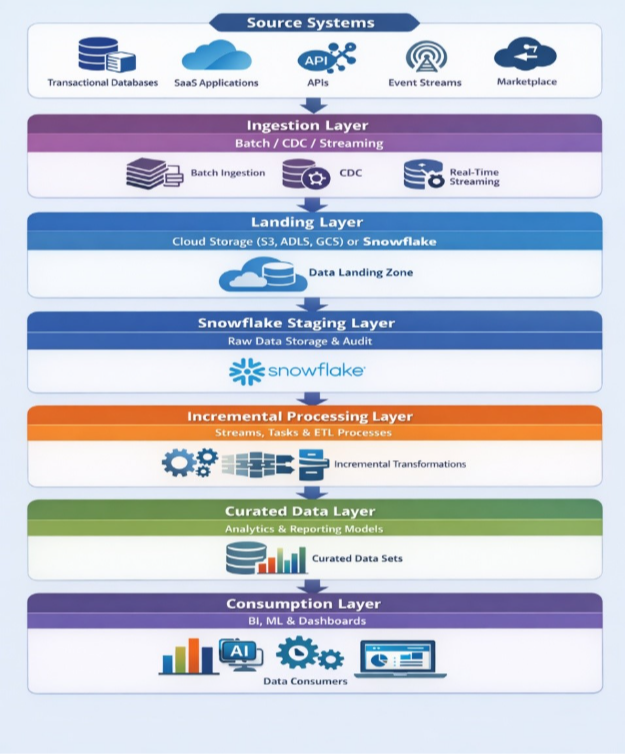
5. Recommended Architecture
5.1 High-Level Flow (End-to-End)
- Source Systems: Data originates from transactional databases, SaaS applications, APIs, and event streaming platforms across the enterprise ecosystem.
- Ingestion Layer (Batch / CDC / Streaming): Data is ingested using the appropriate pattern based on workload requirements, balancing latency, cost, and complexity.
- Landing Layer: Data is staged in cloud storage (S3, ADLS, GCS) or directly ingested into Snowflake for initial processing and persistence.
- Snowflake Staging Layer: Raw data is stored in a centralized staging schema, ensuring traceability, auditability, and consistent downstream processing.
- Incremental Processing Layer: Snowflake Streams and Tasks or ETL tools process data incrementally, applying transformations and handling changes efficiently.
- Curated Data Layer: Data is transformed into structured models optimized for analytics, reporting, and business consumption.
- Consumption Layer: Processed data is consumed by BI tools, machine learning pipelines, dashboards, and downstream applications.
- Idempotency Strategy: All ingestion pipelines are designed to be replay-safe using deterministic keys and MERGE-based operations, ensuring that retries, backfills, or reprocessing do not result in duplicate or inconsistent data.
- Failure Handling & Recovery: Pipelines implement robust error handling including retry strategies with exponential backoff, dead-letter queues (DLQ) for failed records, checkpointing for long-running processes, and partial failure recovery to avoid full pipeline re-execution.
- Schema Evolution Strategy: Pipelines support schema changes through backward compatibility checks, controlled schema propagation, and validation mechanisms before ingestion to prevent downstream failures and ensure stability.
- Observability Layer: End-to-end observability is implemented across pipelines and data, including monitoring of failures and retries, enforcement of data SLAs such as freshness and completeness, and anomaly detection to proactively identify data quality or pipeline issues.
- Scalability & Workload Isolation: The system is designed to scale based on data volume, concurrency, and workload type using multi-cluster warehouses, with separate compute resources for ingestion and analytics to ensure workload isolation and consistent performance under high concurrency.
- Disaster Recovery: Snowflake replication and failover strategies are implemented across regions to ensure business continuity. Recovery Point Objective (RPO) and Recovery Time Objective (RTO) are defined based on business requirements.
- Data Governance: A governance layer is implemented including data cataloging, lineage tracking, and data classification to ensure discoverability, compliance, and controlled data usage.
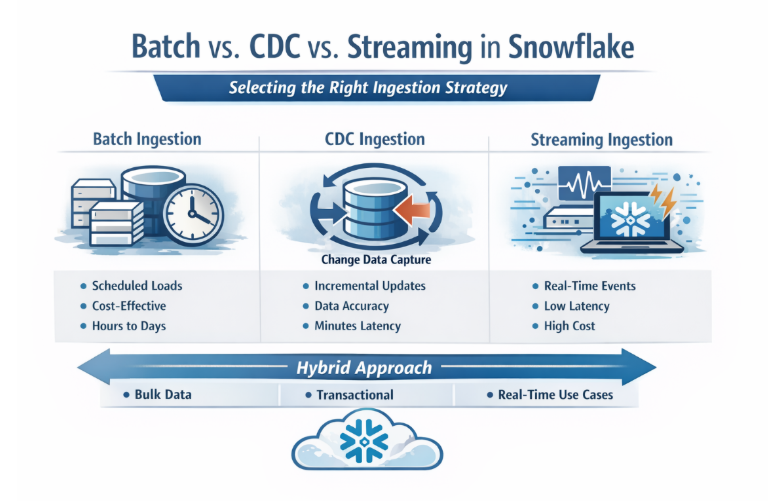
5.3 Options (Ingestion Strategy Comparison)
| Criteria | Batch | CDC | Streaming |
|---|---|---|---|
| Latency | High (hours–days) | Medium (minutes) | Low (seconds) |
| Cost Efficiency | High | Moderate | Low (highest relative cost) |
| Complexity | Low | Medium | High |
| Data Accuracy | Moderate | High | High |
| Best Fit | Reporting, bulk | Transactional systems | Real-time, event-driven |
5.4 Selection Guide (When to Use What)
Batch Ingestion — Use When:
- Data freshness requirements are low and can tolerate scheduled processing intervals. This approach is ideal for large-scale data loads with predictable update cycles.
- Cost efficiency and simplicity are key priorities, especially for reporting and historical data processing workloads.
Avoid Batch When: Near real-time insights are required for operational decision-making. Batch processing introduces latency that may not meet business SLAs.
CDC — Use When:
- Accurate tracking of inserts, updates, and deletes is required for transactional systems. This ensures data consistency across source and target systems.
- Incremental processing is needed to reduce load times and improve efficiency compared to full data reloads.
Avoid CDC When: Source systems do not support change tracking mechanisms, making implementation complex or unreliable.
Streaming — Use When:
- Real-time or near real-time processing is required for event-driven applications and analytics use cases. This enables immediate data availability.
- Business requirements demand low-latency data pipelines for monitoring, alerts, or operational insights.
Avoid Streaming When: The use case does not justify the added complexity and cost of maintaining continuous ingestion pipelines.
5.5 Architectural Recommendation
A hybrid ingestion architecture is recommended for enterprise Snowflake implementations. This approach combines batch, CDC, and streaming patterns based on workload characteristics.
Batch is best suited for bulk data processing, CDC for maintaining transactional consistency, and streaming for real-time use cases. This layered strategy ensures optimal balance between performance, cost efficiency, and scalability.
6. Implementation
6.1 Setup
- Configure Snowflake databases, schemas, warehouses, and roles to establish the foundational data environment. This ensures proper isolation and access control.
- Establish secure connectivity with external systems such as cloud storage, APIs, and databases using IAM roles and secure credentials.
6.2 Core Build Steps
- Classify workloads based on latency requirements, data volume, and change patterns to determine the appropriate ingestion strategy.
- Design and implement ingestion pipelines using batch, CDC, or streaming mechanisms aligned with business requirements.
- Load raw data into Snowflake staging tables to ensure traceability and enable incremental processing.
- Apply transformations using Streams, Tasks, or ETL tools to process data efficiently and maintain consistency.
- Publish curated datasets for analytics, reporting, and downstream consumption.
6.3 Configuration Defaults
- Watermarking strategy: Use timestamp-based watermarking for batch ingestion and log/offset-based tracking for CDC and streaming pipelines.
- Deduplication strategy: Implement deduplication using primary or composite keys to ensure data consistency across ingestion layers.
- Load frequency: Schedule batch loads at defined intervals, while CDC and streaming pipelines operate incrementally or continuously.
- Error handling: Implement retry mechanisms, centralized logging, and failure isolation to ensure pipeline resilience.
7. Validation & Testing
7.1 Data Validation
- Batch validation: Ensure completeness of scheduled loads and verify that no data gaps exist between execution cycles.
- CDC validation: Confirm that all change events (insert, update, delete) are captured accurately and applied in the correct sequence.
- Late-Arriving Data Handling: Pipelines handle out-of-order and late-arriving events using watermarking, event timestamps, and reconciliation strategies to ensure data correctness.
- Streaming validation: Validate continuous data flow, ensuring event ordering, low latency, and handling of duplicate or delayed events.
7.2 Reconciliation
Perform periodic reconciliation with source systems to validate data accuracy and completeness. Compare aggregate metrics and control totals to ensure consistency across ingestion layers.
8. Security & Access
- Implement least-privilege access using RBAC to control data access and maintain security across environments.
- Use centralized secret management systems to securely store and manage credentials and sensitive information.
- Enforce separation of duties between engineering, operations, and analytics teams to reduce risk and improve governance.
- Enable audit logging and monitoring to track data access and ensure compliance with organizational policies.
9. Performance & Cost
9.1 Performance Considerations
Align Snowflake warehouse sizing with ingestion patterns to optimize performance and resource utilization. Optimize data storage using clustering and partitioning strategies to improve query performance.
9.2 Cost Drivers
Compute costs from Snowflake warehouses and task execution contribute significantly to overall expenses. Storage costs include raw data, processed data, and historical retention such as Time Travel.
9.3 Cost Controls
Enable auto-suspend and auto-resume to minimize unnecessary compute usage. Use resource monitors and optimize ingestion frequency to control and predict costs effectively.
10. Operations & Monitoring
10.1 What to Monitor
Monitor pipeline execution success rates and identify failures to ensure reliability. Track data freshness and latency to ensure SLAs are consistently met.
10.2 Alerting
Configure alerts for pipeline failures and SLA breaches to enable proactive issue resolution. Monitor cost anomalies and unusual data volume spikes to prevent unexpected issues.
10.3 Runbook (Top Issues)
| Issue | Fix |
|---|---|
| Pipeline failure | Restart from the last successful checkpoint to ensure data continuity. |
| Data duplication | Apply deduplication logic and validate key constraints to maintain accuracy. |
| Latency issues | Scale compute resources or adjust ingestion frequency to meet SLAs. |
11. Common Pitfalls
- Overusing streaming for workloads that do not require real-time processing increases cost and complexity.
- Ignoring delete handling in CDC pipelines leads to inaccurate datasets and reporting issues.
- Poor watermark management results in data gaps or duplication across ingestion layers.
- Lack of schema evolution handling causes pipeline failures when source structures change.
- Missing monitoring and alerting reduces visibility into pipeline performance and failures.
12. Variations / Use Cases
- API-based ingestion for SaaS platforms: Enables integration with external systems such as HR and payroll applications.
- CDC pipelines for transactional databases: Ensures accurate and efficient data synchronization.
- Batch ingestion: Supports large-scale reporting and historical data analysis use cases.
- Streaming ingestion: Enables real-time analytics and event-driven applications.
13. Next Steps
- Define an enterprise-wide ingestion decision framework to standardize architecture practices.
- Conduct workload assessments to classify ingestion patterns based on business requirements.
- Implement pilot pipelines using Snowflake-native capabilities to validate design choices.
14. Appendix
- Reference architectures for batch, CDC, and streaming ingestion patterns.
- Sample configuration templates and best practices for Snowflake ingestion pipelines.
- Glossary of key concepts including batch processing, CDC, streaming, and watermarking.
Conclusion
Snowflake provides powerful capabilities, but the real value comes from using the right ingestion pattern in the right context.
A simple way to think about it:
- Batch: Efficient for large, scheduled data loads.
- CDC: Tracks and applies incremental changes accurately.
- Streaming: Enables real-time, event-driven data ingestion.
When combined through a hybrid architecture, these patterns help build scalable, cost-efficient, and low-maintenance data pipelines. The key is not to overuse any single approach, but to align ingestion strategy with business requirements, data characteristics, and SLA expectations.

Jagadishwar Pannala
Associate Data Engineer
Boolean Data Systems

Jagadishwar Pannala is a Data Engineer at Boolean Data Systems, specializing in building scalable data pipelines and modern cloud data platforms. He focuses on data migration and cloud-based data engineering, with expertise in Snowflake, cloud data architectures, and ETL/ELT pipeline development to support reliable and efficient enterprise analytics.
About Boolean Data
Systems
Boolean Data Systems is a Snowflake Select Services partner that implements solutions on cloud platforms. we help enterprises make better business decisions with data and solve real-world business analytics and data problems.
Services and
Offerings
Solutions &
Accelerators
Global
Head Quarters
USA - Atlanta
3970 Old Milton Parkway,
Suite #200, Alpharetta, GA 30005
Ph. : 770-410-7770
Fax : 855-414-2865